Oppai-Detectとは?
画像のおっぱい部分を自動認識させる挑戦である。
目的
筆者はおっぱいが好きだ。そこでおっぱい画像をたくさん集めたい。 例えばその際に収集の精度を高めたいと思う。 そこで、おっぱい部分を自動で検出したらそれが可能になると考える。
応用例
Oppai-Detectの社会的に貢献できる応用例は以下である。
- 放送禁止画像の検出(画像投稿サイトなど)
- スパム画像対策
- 青少年向け、サイトフィルタリング
また、これを逆手に取ればおっぱい画像が勝手にたくさん集まるという筆者の企みもある。
手法
Intelが開発・公開したオープンソースの画像処理ライブラリ「OpenCV」を使用した。 これはパターン認識としての物体検出(Object-Detect)の機能を備えている。 画像認識において、学習(Training)と検出(Detection)がOppai-Detectにおいて重要な概念である。
OpenCVによる顔認識の例
OpenCVライブラリ付属の「haarcascade_frontalface_alt2.xml」という顔部分検出用のデータを利用すれば、 簡単に画像からの顔検出が可能だ。 以下がPerlでの実装例である。
use Image::ObjectDetect;
use Imager;
my $file = $ARGV[0] or die 'Filename is needed!';
my $img = Imager->new;
$img->read( file => $file ) or die $img->errstr;
my $cascade = './haarcascade_frontalface_alt2.xml';
my $detector = Image::ObjectDetect->new($cascade);
my @faces = $detector->detect($file);
for my $face (@faces) {
$img = $img->box(
xmin => $face->{x},
xmax => $face->{x} + $face->{width},
ymin => $face->{y},
ymax => $face->{y} + $face->{height},
color => 'red',
filled => 0,
) or die $img->errstr;
}
$img->write( file => 'out.jpg' ) or die $img->errstr;
上記のコードを実行した例が以下の写真である。 顔の部分が自動検出され赤い枠で囲まれているのがわかる。

今回のチャレンジ
以下の3つの行程を行い、おっぱい画像検出用のデータを学習させることをチャレンジとした。
- 画像を集める
- 学習ツールを作成
- ひたすらおっぱいを囲む
学習に必要な画像
学習では「Positive Image」及び「Negative Image」という二つの画像が必要になる。 Positive Imageとは対象物、つまりこのケースではおっぱいが写っている画像のことで、 精度の高い学習には7000から8000枚の画像が必要になる。 また、Negative Imageとは対象物が写ってない画像である。
1.画像を集める
学習のためにおっぱい画像が必要になる。 これは「いかにして大量のおっぱい画像を集めるか」という命題である。 今回は、画像検索サイトのWeb APIを利用して画像のURLを取得した。 ただ、これには問題がある、例えばYahoo! 画像検索 APIでは一つの検索クエリーにつき、 最大の検索結果取得件数が1,000件となり、数としては不十分である。 最低でも1万件以上は集めたい。 そこで、AV女優のリストを駆使して解決することにした。つまり AV女優の名前と「おっぱい」という文字列を連結したものを検索クエリーとしたものを 大量に用意し、複数回Web APIを叩くわけである。
- 検索クエリー「AV女優A おっぱい」で検索
- 検索クエリー「AV女優B おっぱい」で検索
- 検索クエリー「AV女優C おっぱい」で検索
- ...
という具合だ。
AV女優のリストには拙作のPerlモジュール「Acme::Porn::JP」を利用した。 以下のコードがAcme::Porn::JPの今回のケースでのSYNOPSISである。
use Acme::Porn::JP;
...;
my $porn = Acme::Porn::JP->new;
my $actress_list = $porn->actress();
for my $actress ( @$actress_list ){
search("おっぱい $actress");
}
...;
このAcme::Porn::JPの現行バージョンでは4502人のAV女優名が掲載されている。 Acme::Porn::JPは以下のgithubサイトから入手できる。
http://github.com/yusukebe/Acme-Porn-JP
その結果29,065枚の画像を入手することができた。
Haartrainingツールによる学習
OpenCVに付属のHaartrainingというツールを使って画像学習ができる。 手順例は以下の通り。「2」及び「3」はコマンドラインソフトで実現できるので、 「1」を今回は行えばよいことになる。
- positive.dat/negative.dat の作成
- コマンドラインの実行「$ opencv_createsamples -info positive.dat -vec a.vec」
- コマンドラインの実行「$ opencv_haartraining -data haarcascade -vec a.vec -bg negative.dat -nstages 20」
ちなみに、positive.datとはPositive Imageの集合を表し、 画像ファイルへのパス、対象物の数、対象物の座標情報を記載するプレーンテキストファイルである。 negative.datはNegative Imageの画像ファイルへのパスのリストである。
positive.dat [filename] [# of objects] [[x y width height] [... 2nd object] ...] images/01.jpg 1 140 100 45 45
negative.dat images/neg-01.jpg images/neg-02.jpg
2.学習ツール作成
今回はpositive.dat及びnegative.datを生成する学習のためのツールを作成した。 ユーザーは収集した画像を閲覧し、 その中に対象物、つまりこの場合ではおっぱいがあれば囲む作業を行う。 プログラムは囲まれた部分の座標情報とファイル名をpositive.datに書き込む。 画像に対象物が無ければ、ユーザーはスキップをすることができ、 こうした際にはnegative.datにファイル名が書き込まれることになる。
画像の閲覧・囲い作業はWebブラウザでできるように考慮した。 HTTPプロトコルのWebアプリケーション、またJavascriptによるフロントエンドが実装されている。 これを「Haartraining-App」と名付け、githubで入手可能になっている。
http://github.com/yusukebe/Haartraining-App
Haartraining-Appの一般的なディレクトリ構成は以下の通りである。
yusuke@macmini:~/work/oppai-detect/temp/Haartraining-App$ tree ./
./
|-- data
| |-- images
| | `-- 000001.jpg
| |-- negative.dat
| `-- positive.dat
|-- haartraining.psgi
`-- html
|-- haartraining.js
`-- index.html
3 directories, 6 files
Plackモジュールのplackupコマンドを使えば起動しているホストの5000番ポートなどで、 アプリケーションが起動する。
$ plackup haartraining.psgi
3.ひたすらおっぱいを囲む
あとはひたすらおっぱいを囲む作業を行う。 下の画像はイメージである。
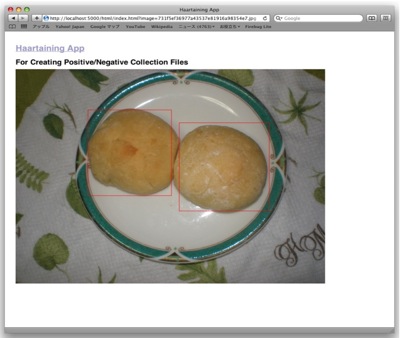
opencv_haartrainingによる学習
positive.dat、negative.datの準備ができたら、 OpenCVコマンドラインプログラムで学習を行う。 今回のケースではPositive Imageが1000枚程度、対象物の数約2000個つまり「2000乳」を学習させた。 Mac mini / OSX 10.5 (2.26 GHz Intel COre 2 Duo)の環境で、 3日間を要した。
実験
学習結果としての検出ファイルを利用し、画像からのおっぱい部分の検出を実験してみた。 実験プログラムの一つに検出した部分を「18禁マーク」で覆うという物があるが、 それを使用して出力された画像の一つが以下である。

上のように正面を向いたおっぱいで、画像の大きさが的確ならば比較的認識されやすいことがわかった。 また、誤認識も見受けられ、「へそ」や腕の一部など「膨らんでいる部位」がおっぱいとして認識されてしまった。
考察
おっぱい画像の学習行程において、 おっぱいにも正面乳、横乳、下乳、上乳、微乳、巨乳などたくさんあることを非常に考えさせられた。 付け加え、どこまでがおっぱいであるかという倫理的、哲学的な問題にも直面した。 また、おっぱいを囲む作業は非常に楽しいことであるが、時間がかかるので、 学習コストがかかるという印象である。
今後
考察にある問題点を解決するために、 まず、多様なおっぱいに対するポリシーを策定する必要がある。 次に、今回実装した学習ツールブラッシュアップしクラウド環境で運用したいと感じている。 その結果Oppai-Detect学習のソーシャル化が実現され「みんなで作るOppai-Detect」が実現する。 今後もおっぱいを楽しめるOppai-Detectを目指す。
参考資料
Oppai-Detect 3
View more presentations from yusukebe.