はてなブックマークを新聞風に表示し、閲覧できるHatebuPaperなるものを作ってみました。 今日の午前1時に作り出して、7時に公開したので賞味6時間で完成です。
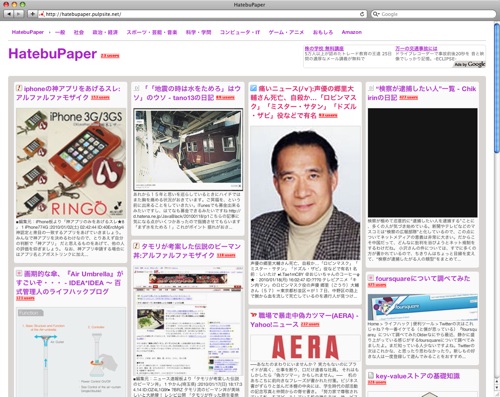

以前からはてなブックマークをより視覚的に見たいなーと思っていました。 最近では本体の方でもエントリーによってはそのページに含まれる画像のサムネイルを表示してくれたりします。 が、ちょっとそれだけじゃあ物足りないなーということで、 まずは記事から特徴的なそこへ張られているイメージのURLを取って来れないか というのが始まりでした。
で、一度 tokuhirom ware の HTML::LDRFullFeed と(それが失敗した場合に) HTML::TokeParser で、 本文抽出を行い、その中で一番先頭に来る img タグを記事の特徴画像と見なすという 簡単なロジックを考えやってみたところ、まーそこそこ。 で、なんとなくかっこよーく表示させたいなぁと思っていたら、 jQueryのpluginで、 jQuery Masonry というもの発見。 すげーはしょって、説明するとCSSのFloatレイアウトを「詰めて」かっこよくしてくれる便利なものです。 ということでそれらをミックスする形でHatebuPaperができましたとさ。
結構サクサクと動いて気に入ってます。 以下に、ウェブページから特徴的な img タグの src 属性を出力する簡単なサンプルを 貼付けておきます。ということで Enjoy!
use strict;
use warnings;
use HTML::ExtractContent;
use HTML::TokeParser;
use HTML::LDRFullFeed;
use LWP::UserAgent;
my $url = shift || 'http://yusukebe.com/';
my $ldrfullfeed = HTML::LDRFullFeed->new();
my $ua = LWP::UserAgent->new;
my $res = $ua->get($url);
my $src = $ldrfullfeed->make_full( $url, $res->content );
unless ($src) {
my $extractor = HTML::ExtractContent->new;
$extractor->extract( $res->decoded_content );
$src = $extractor->as_html;
}
my $p = HTML::TokeParser->new( \$src );
while ( my $token = $p->get_tag("img") ) {
print $token->[1]{src} . "\n";
}

posted with yusukebe.com::AmazonSearch on 2010.1.19
- 大型本 / 技術評論社
- Amazon 売り上げランキング: 80156
- Amazon おすすめ度の平均:

-
 「特に面白かった」、「はてなブックマーク構築ノウハウ大公開」
「特に面白かった」、「はてなブックマーク構築ノウハウ大公開」 -
 レコメンドエンジン
レコメンドエンジン
-

posted with yusukebe.com::AmazonSearch on 2010.1.19
- 小林 祐一郎 できるシリーズ編集部
- 新書 / インプレスジャパン
- Amazon 売り上げランキング: 360345